

物体検出のための内容・位置統合特徴の自己教師あり学習
近年、画像から有用な特徴を抽出するための自己教師あり学習(Self-Supervised Learning, SSL)が大きな進展を遂げています。特に、ラベル付きデータを使わずに大量の画像データから特徴を学習し、画像分類 […]
続きを読む
何を“検出すべきか”は誰が決めるのか:OSOD研究の課題と新たな問題設定
近年、物体検出技術の進展により、画像中に存在する対象物(オブジェクト)を高精度に検出・分類することが可能になってきた。しかし、現実世界のアプリケーションでは、学習時に見たことのない未知クラスの物体に遭遇することが多く、そ […]
続きを読む
マルチモーダルAIによる地すべり画像解析と災害リスク評価
近年、気候変動の影響により世界各地で自然災害が頻発している。特に地すべり災害は、発生後に地形が大きく変化するため、被害の拡大や二次災害のリスクが高く、迅速かつ高度な状況把握が求められている。しかしながら、こうした災害現場 […]
続きを読む
RefVSR++: 参照映像を活用した高精度な動画超解像手法
本研究は、スマートフォン等に搭載されるマルチカメラシステムの特性を活用し、低解像度映像を高解像度に復元する参照ベース動画超解像(*)に関する手法「RefVSR++」を提案するものである。従来の動画超解像手法では、単一の低 […]
続きを読む
セマンティックセグメンテーションのためのドメイン適応
本論文は,セマンティックセグメンテーションにおける教師なしドメイン適応(UDA)の精度向上を目的として,新たな手法「クロスリージョン適応(CRA)」を提案している。セマンティックセグメンテーションは画像内の各画素に意味的 […]
続きを読む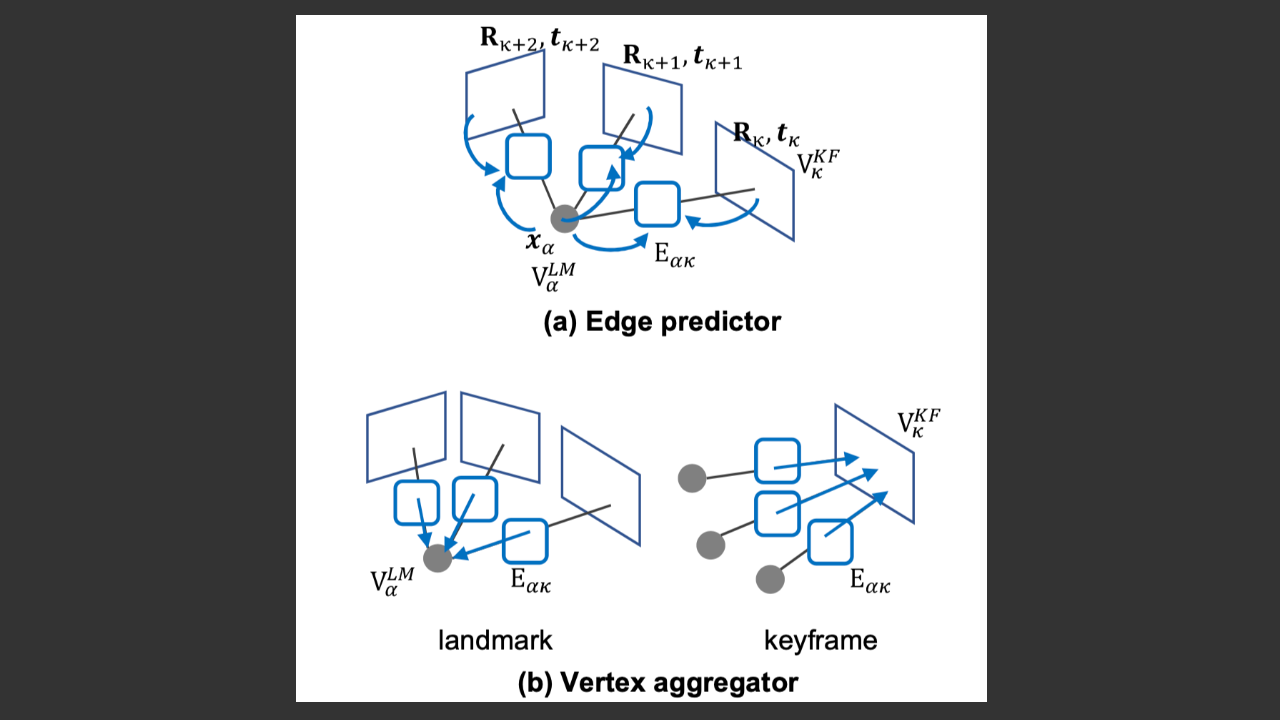
車両SLAM高速化のためのグラフネットワークによる高速バンドル調整
SfMや視覚SLAMの分野において、バンドル調整(BA)はカメラ姿勢と3次元ランドマークの位置を最適化する重要なプロセスである。実際、多くの視覚SLAMシステムでは、局所的に最新数フレームのキー フレームとそのランドマー […]
続きを読む
局所特徴統合による高速高精度視覚ローカライゼーション
視覚的ローカライゼーションは、SfMやSLAMなど、多くのコンピュータビジョン応用においてカメラの6自由度姿勢を推定するための重要な課題である。従来の手法は、画像検索に用いるグローバル特徴と、精密な姿勢推定に必要な局所特 […]
続きを読む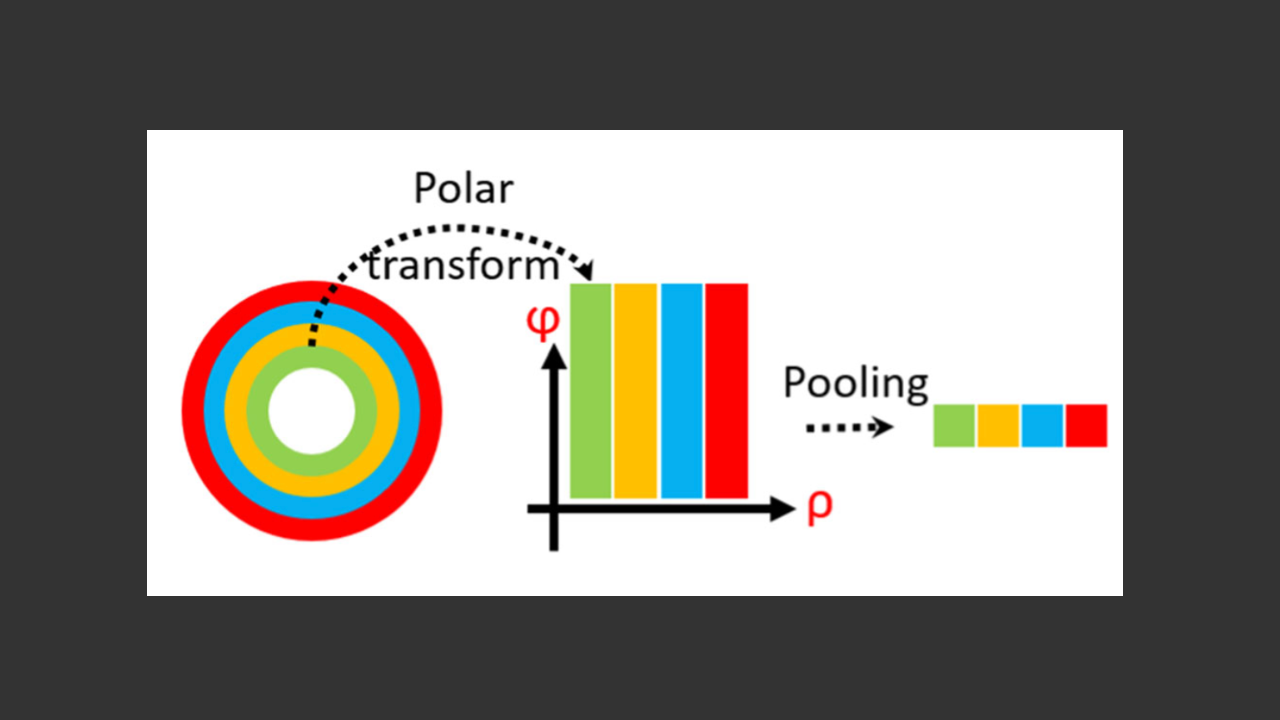
問題の対称性を活用した身体化視覚ナビゲーション
自律移動ロボットや拡張現実などの分野で注目される身体化(embodied)視覚ナビゲーションは、未知環境内でロボットが自己の位置を認識しながら探索や目標物体の捜索を行うために不可欠な技術である。しかし、これまでの深層強化 […]
続きを読む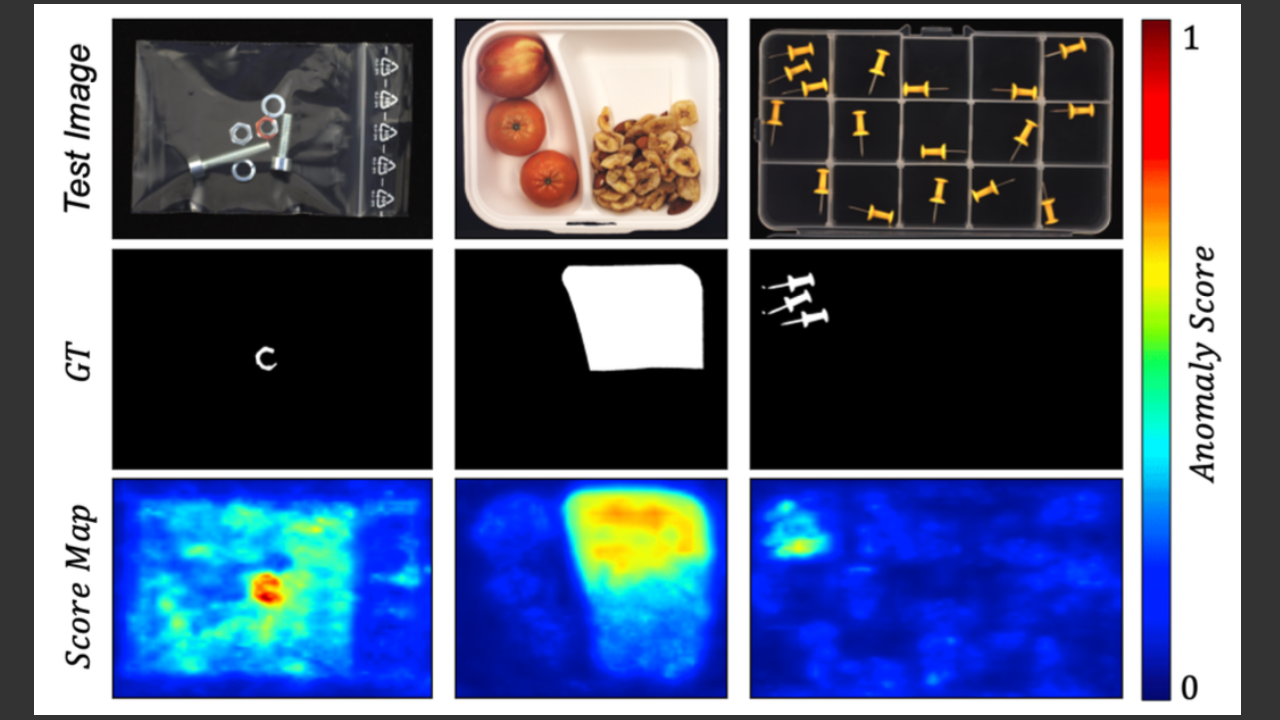
局所と全体の知識統合に基づく画像からの論理的及び構造的異常検出
本研究は、工業製品の検査などで重要な異常検出の課題に対して、従来手法では捉えにくかった「論理的異常」(例えば、部品の配置ミスや欠落など画像全体の文脈情報に依存する異常)を高精度に検出する新たな手法を提案している。従来の異 […]
続きを読む
GRIT: グリッド+リージョン特徴を活かした画像キャプショニング
画像に写っている風景や物体を文章で説明する「画像キャプショニング」は、人工知能が視覚情報を言葉で表現する技術の一つである。最近の主流の手法では、まず画像から「特徴量」と呼ばれる情報を抽出し、それをもとに自然な文章を生成す […]
続きを読む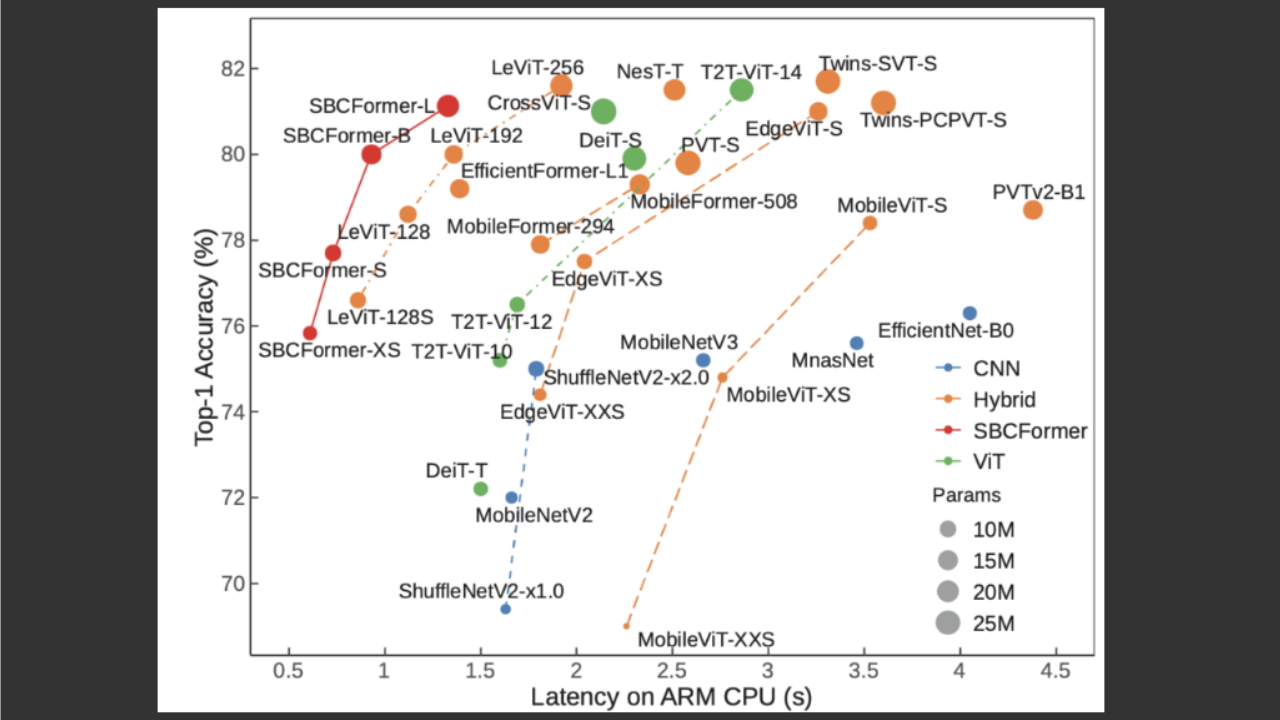
SBCFormer: シングルボードコンピュータで動作可能な軽量画像認識モデル
近年、ディープラーニングによる画像認識は農業、漁業、畜産などの実世界の応用に広がりつつある。これらの応用では、高速な処理よりも低コスト・低消費電力なシステムが求められ、シングルボードコンピュータ(SBC)上での実行が重要 […]
続きを読む
橋梁検査のための対話型マルチモーダルAI——————–
本論文は、橋梁点検の自動化を目的として、画像と自然言語の両方を扱うマルチモーダルAI技術を用いた視覚的質問応答(VQA)の性能向上に取り組んだ研究である。従来、橋梁の検査は熟練した専門家による目視確認が中心であり、作業時間や人件費がかかる上に、検査結
続きを読む
ゼロショットテクスチャ異常検知
近年、工業検査や品質管理において、画像中の異常検知の重要性が高まっている。特に、テクスチャ画像の異常検知は、従来の多くの手法が多数の正常画像を前提とする中で、入力画像と正常画像の向きが一致しない場合に精度が低下する問題が […]
続きを読む
交通シーンの理解に基づく運転危険予測
近年、自動運転技術や先進運転支援システム(ADAS)の発展に伴い、車両周囲の危険予測は安全運転において極めて重要な課題となっている。従来の手法は動画解析やシミュレーションに依存し、短時間内の異常検知が主流であったが、本研 […]
続きを読む