SBCFormer: An Image Recognition Model for Single Board Computers
- Post by: admin
- 2025-03-26
- No Comment
In recent years, deep learning-based image recognition has expanded into practical applications such as agriculture, fisheries, and livestock management. In these domains, low-cost and low-power systems are often more important than high-speed processing, making single board computers (SBCs) an appealing platform. However, many lightweight neural networks developed thus far have been designed with smartphones in mind, and their performance and speed are limited on low-spec CPUs such as those found in devices like the Raspberry Pi.
This study proposes “SBCFormer,” a lightweight CNN-ViT hybrid architecture optimized for inference on SBCs. It is specifically designed to operate under limited computational resources while maintaining high recognition accuracy, even on devices without GPUs.
Design Motivation and Challenges
The self-attention mechanism in Transformers offers advantages on low-end CPUs due to its relatively simple memory access patterns compared to convolutions, which require complex memory operations. However, self-attention suffers from quadratic computational complexity with respect to the number of tokens, making it inefficient on high-resolution feature maps.
To address this, SBCFormer introduces a two-stream structure that applies attention to a downsampled version of the input, thereby reducing the computational burden while preserving essential local information through a separate stream.
Two-Stream Structure and Attention Enhancement
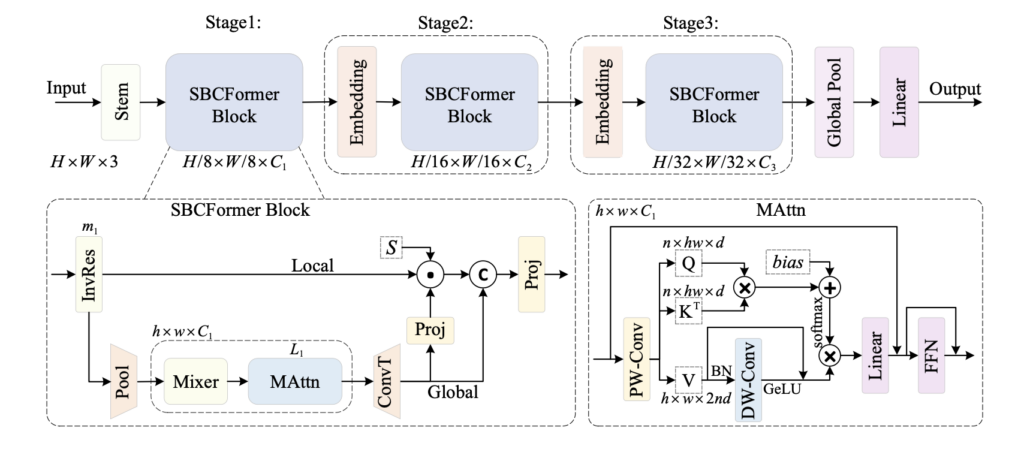
Each block in SBCFormer starts with an Inverted Residual Block (InvRes), inspired by MobileNetV2, which performs initial feature extraction. The resulting feature map then splits into two streams:
- Global Stream: The feature map is downsampled (e.g., to 7×7), attention is applied, and it is upsampled back to the original resolution. This captures global context at low computational cost.
- Local Stream: The feature map bypasses downsampling and attention, preserving fine-grained local details.
The two streams are then merged by applying a learned attention-based weighting mechanism and concatenating the results. This design combines global and local information efficiently.
To enhance the representational power of the attention mechanism on low-resolution maps, the authors introduce a modified attention module that incorporates depth-wise convolution, GeLU activation, and batch normalization into the value component of attention, improving expressiveness without excessive computational cost.
Experimental Results
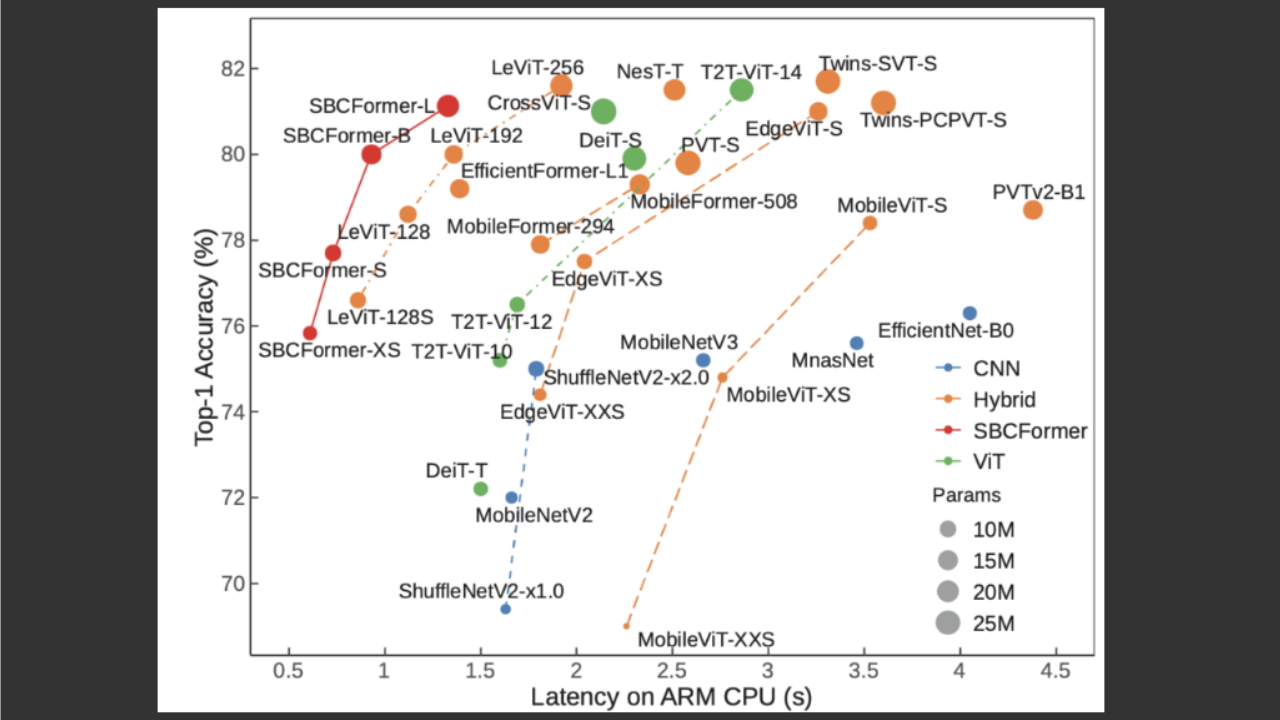
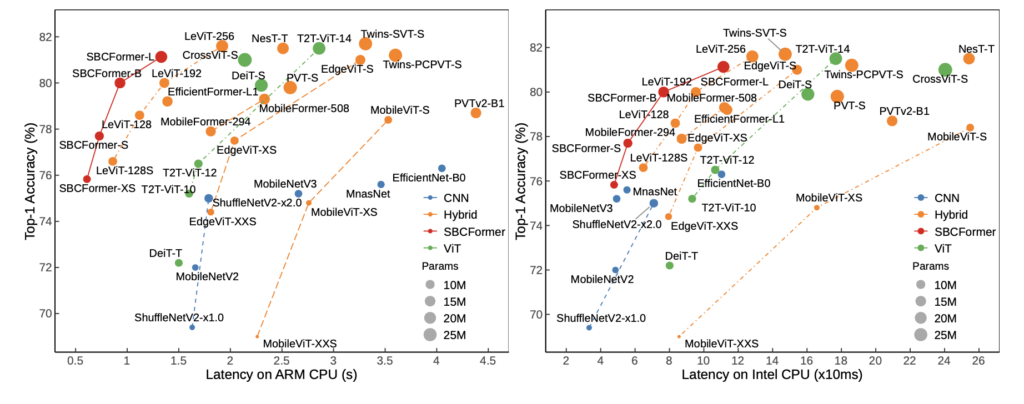
The proposed model was evaluated on the ImageNet-1K classification task. On the Raspberry Pi 4 (with an ARM Cortex-A72 CPU), SBCFormer-B achieved a top-1 accuracy of 80% while maintaining an inference speed of 1 frame per second. This performance surpasses existing lightweight CNNs (e.g., MobileNetV2/V3, EfficientNet) and hybrid models (e.g., EdgeViT, MobileViT) in terms of accuracy-latency trade-off on low-end CPUs.
An ablation study confirmed the effectiveness of both the dual-stream architecture and the enhanced attention mechanism. Furthermore, SBCFormer was tested as a backbone in object detection (RetinaNet) using the COCO dataset, showing comparable or better accuracy than other backbones with similar parameter sizes.
Conclusion and Outlook
SBCFormer achieves a strong balance between inference accuracy and computational efficiency on low-end CPUs, leveraging the strengths of attention mechanisms while mitigating their computational drawbacks. Its design is particularly suitable for edge applications where GPU resources are unavailable and power efficiency is critical.
However, the evaluations are based on specific hardware (Raspberry Pi 4 and Intel CPUs), and results may vary on other platforms. Inference latency is also influenced by various environmental factors such as compiler optimization, OS, and framework.
Future work includes further model compression, adaptation to other edge environments, and application to additional vision tasks.
Publication
Lu, Xiangyong, Masanori Suganuma, and Takayuki Okatani. “Sbcformer: lightweight network capable of full-size imagenet classification at 1 fps on single board computers.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.
@inproceedings{lu2024sbcformer,
title={Sbcformer: lightweight network capable of full-size imagenet classification at 1 fps on single board computers},
author={Lu, Xiangyong and Suganuma, Masanori and Okatani, Takayuki},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={1123--1133},
year={2024}
}