
GRIT: Transformer-based Image Captioning Leveraging Grid and Region Features
- Post by: admin
- 2025-03-26
- No Comment
“Image captioning,” the task of describing the scenery and objects in an image using natural language, is one of the technologies in artificial intelligence that enables visual information to be expressed in words. In recent mainstream approaches, features—informative representations extracted from the image—are first obtained and then used to generate natural-sounding captions. The quality and type of these features greatly influence the performance of the model.
Previously high-performing methods have relied on object detectors to identify individual objects in an image—such as “dog” or “car”—and extract region-based features corresponding to these detected areas. However, this approach presents several challenges. It struggles to capture contextual relationships between objects, can miss important items due to detection errors, and is computationally expensive, making the overall model more complex to train.
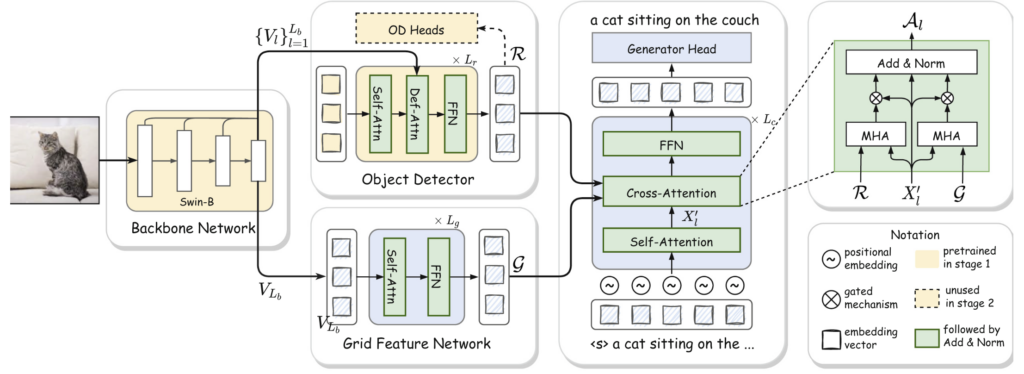
In contrast, the newly proposed method called “GRIT” aims to balance accuracy and efficiency by combining two types of features: region features from object areas and grid features obtained by dividing the entire image into a grid. Grid features provide broader coverage of the image, including context and background, but are less effective at identifying specific objects. GRIT is designed to effectively fuse these two complementary types of information, compensating for each other’s weaknesses.
From a technical standpoint, GRIT replaces the commonly used CNN-based object detectors with a Transformer-based model known as “DETR.” This allows for faster feature extraction and enables end-to-end training of the entire model. Furthermore, the caption generation component, also based on Transformer architecture, incorporates a unique cross-attention mechanism that simultaneously leverages both types of visual features, allowing for more expressive and nuanced captions.
Experimental results have shown that GRIT achieves higher scores than previous methods on standard datasets like COCO, while also being faster. Notably, GRIT matches or exceeds the performance of state-of-the-art models, even without relying on large-scale pretraining.
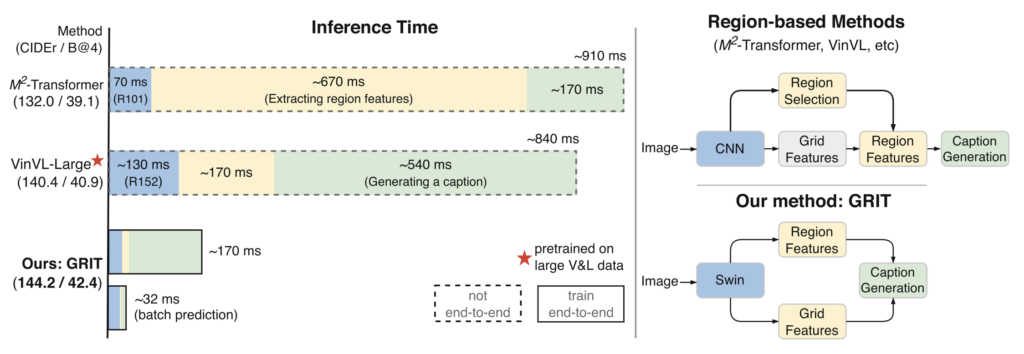
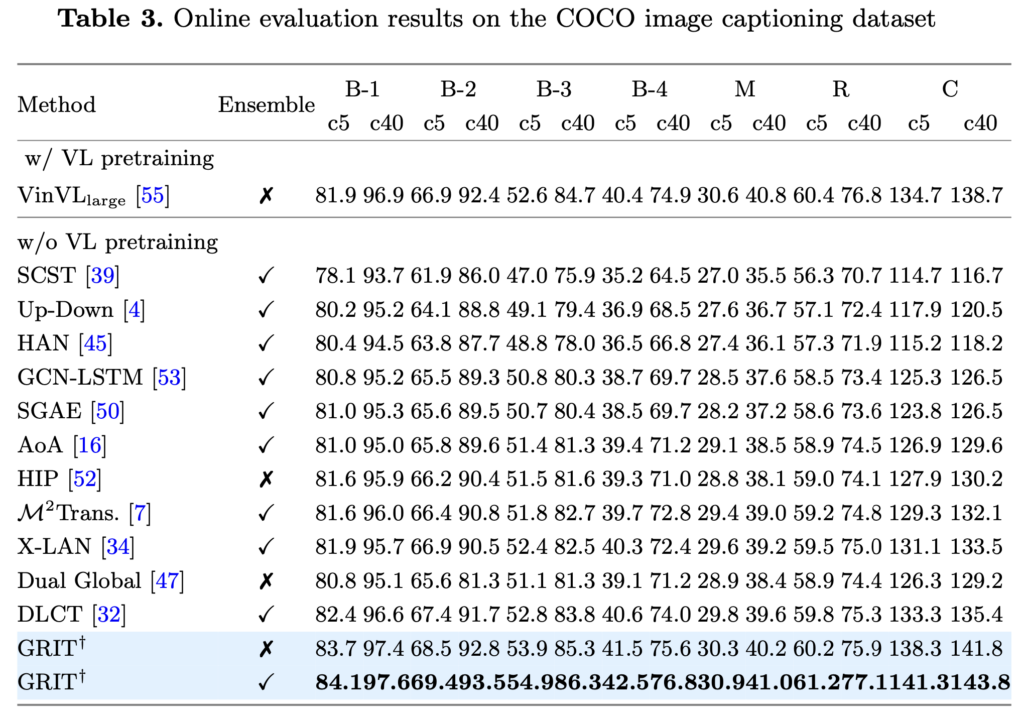
In summary, GRIT represents a significant advancement in image captioning, combining a unified Transformer-based architecture with effective use of dual visual features. It holds promise for a wide range of applications that require the integration of vision and language.
Publication
Nguyen, Van-Quang, Masanori Suganuma, and Takayuki Okatani. “Grit: Faster and better image captioning transformer using dual visual features.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
@inproceedings{nguyen2022grit,
title={Grit: Faster and better image captioning transformer using dual visual features},
author={Nguyen, Van-Quang and Suganuma, Masanori and Okatani, Takayuki},
booktitle={European Conference on Computer Vision},
pages={167--184},
year={2022},
organization={Springer}
}