
交通シーンの理解に基づく運転危険予測
- Post by: admin
- 2025-03-14
- Comments off
近年、自動運転技術や先進運転支援システム(ADAS)の発展に伴い、車両周囲の危険予測は安全運転において極めて重要な課題となっている。従来の手法は動画解析やシミュレーションに依存し、短時間内の異常検知が主流であったが、本研究では「視覚的アブダクション推論」という人間の推論過程に近いアプローチを採用し、静止画1枚から将来の事故リスクを予測する新たな枠組みを提案している。
提案手法
本研究は、車載ダッシュカムから取得した静止画と走行速度という限られた情報のみを用いて、数秒後に起こりうる事故の可能性を推定することを目的としている。そのために、画像と言語の両方の情報を統合するマルチモーダルAI技術を活用する。具体的には、オープンソースのCLIPモデルを基盤とし、画像とテキストの特徴をより高次元で融合させるために、追加のTransformer層を導入した。これにより、複数の物体間の空間的・因果関係を捉え、視覚的アブダクション推論を実現する手法が構築された。
データセットと評価方法
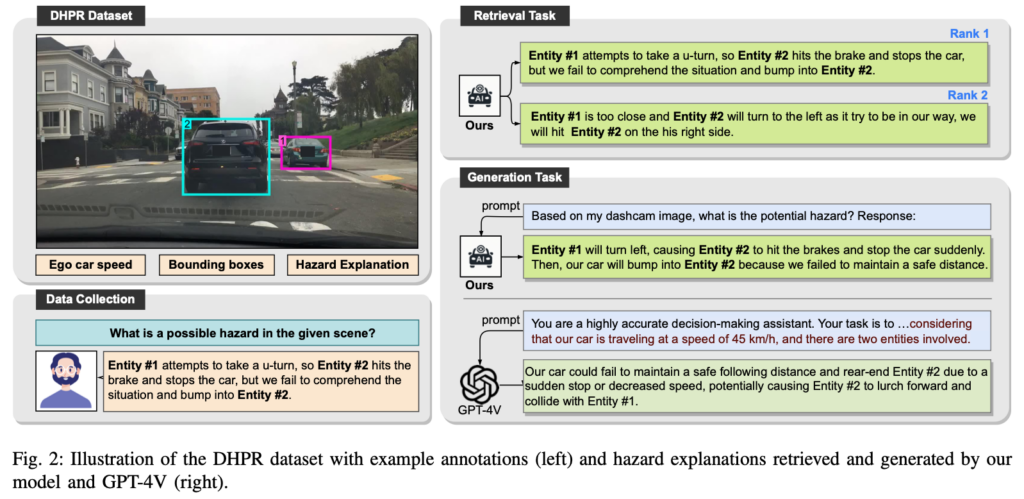
本研究では、既存のダッシュカム画像データセットであるBDD100KやECPから、危険なシーンが推定可能な約15,000枚の画像を厳選し、DHPR(Driving Hazard Prediction and Reasoning)データセットとして公開している。各画像には車両の速度、危険シナリオを示す自然言語の説明、そして事故の発生要因となる最大3つの物体のバウンディングボックスが付与されている。評価は、画像から適切な危険説明文を検索するタスクや、説明文を自動生成するタスクに対して、ランキング指標やBLEU、ROUGE、CIDEr、SPIDErといった評価指標、さらにはGPT-4による意味的評価を用いて行われた。
実験結果と考察
実験結果から、本研究で提案したモデルは従来のBLIP系モデルやその他の既存手法に比べ、画像とテキストの融合による危険予測タスクにおいて優れた性能を示した。また、各構成要素(強力な視覚エンコーダ、追加のTransformer層、エンティティのシャッフル手法など)の有効性を示すアブレーションスタディも実施され、各要素が最終的な予測精度向上に寄与していることが確認された。さらに、静止画のみの入力にもかかわらず、人間の直感的な判断に近い事故シナリオの予測が可能である点が評価され、実用化への可能性が示唆された。

結論と今後の展望
本研究は、従来の動画解析やシミュレーション手法とは異なり、単一画像から複雑な因果関係を推論する視覚的アブダクション推論に基づく新しいアプローチを提示した。これにより、限られた情報から将来の事故リスクを予測することが可能となり、自動運転や運転支援システムの安全性向上に寄与することが期待される。一方で、動画や他の車両データの統合によるさらなる性能向上の可能性や、現実の多様なシナリオに対する適応性の検証が今後の課題として挙げられる。将来的には、より多様な入力データを活用した統合的な危険予測システムの開発が望まれる。
発表論文
Charoenpitaks, Korawat, et al. “Exploring the Potential of Multi-Modal AI for Driving Hazard Prediction.” IEEE Transactions on Intelligent Vehicles (2024).
@article{charoenpitaks2024exploring,
title={Exploring the Potential of Multi-Modal AI for Driving Hazard Prediction},
author={Charoenpitaks, Korawat and Nguyen, Van-Quang and Suganuma, Masanori and Takahashi, Masahiro and Niihara, Ryoma and Okatani, Takayuki},
journal={IEEE Transactions on Intelligent Vehicles},
year={2024},
publisher={IEEE}
}