
GRIT: グリッド+リージョン特徴を活かした画像キャプショニング
- Post by: admin
- 2025-03-26
- No Comment
画像に写っている風景や物体を文章で説明する「画像キャプショニング」は、人工知能が視覚情報を言葉で表現する技術の一つである。最近の主流の手法では、まず画像から「特徴量」と呼ばれる情報を抽出し、それをもとに自然な文章を生成する。このとき、どのような特徴量を使うかが、性能を大きく左右する。
これまで高性能とされてきた手法は、物体検出器を使って画像中の個別の物体(たとえば「犬」や「車」など)を見つけ出し、それぞれの領域ごとの情報(リージョン特徴)を使っていた。しかし、こうした方法には問題も多い。物体の間の関係性といった文脈情報をうまく表現できなかったり、検出ミスで重要なものを見逃す可能性がある。また、計算コストも高く、モデル全体の学習が複雑になるという課題もあった。
これに対して、今回提案された「GRIT」という手法では、2種類の特徴量──物体領域からの情報(リージョン特徴)と、画像全体をグリッド状に分割して得る情報(グリッド特徴)──を組み合わせて利用することで、精度と効率の両立を目指している。グリッド特徴は、画像全体を網羅するような情報であり、文脈や背景も含めた理解に優れている。一方で、細かな物体の識別には弱い。GRITではこの2つの特徴をうまく融合させることで、互いの欠点を補完し合う設計になっている。
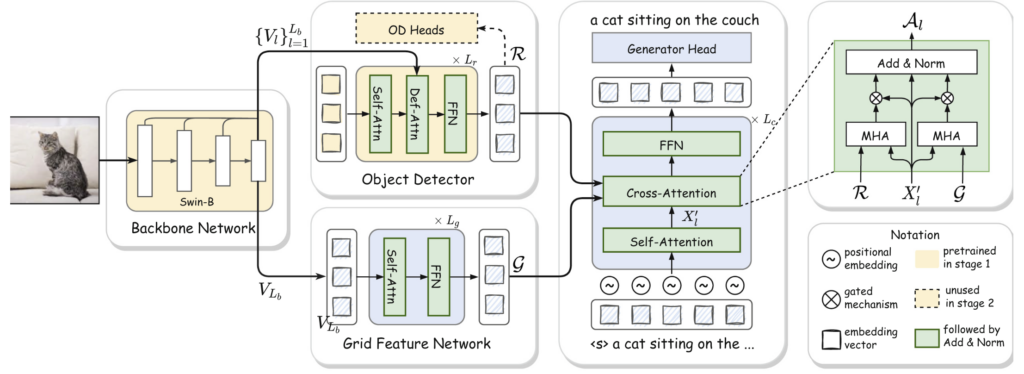
技術的な工夫として、GRITは従来よく使われていたCNNベースの物体検出器の代わりに、Transformerという構造を使った「DETR」と呼ばれるモデルを採用している。これにより、画像からの特徴抽出を高速化し、モデル全体を一括で学習できるようにしている。また、文生成の際には、Transformerベースのキャプション生成器が、2種類の視覚特徴を並行して活用する特別な注意機構(クロスアテンション)を備えており、より豊かな表現が可能になっている。
実験では、GRITがCOCOなどの標準的な画像キャプションデータセットにおいて、既存の手法よりも高いスコアを記録し、速度面でも優れていることが示された。特に、GRITは大規模な事前学習を用いないにもかかわらず、従来の最先端モデルに匹敵、あるいは上回る精度を達成している。
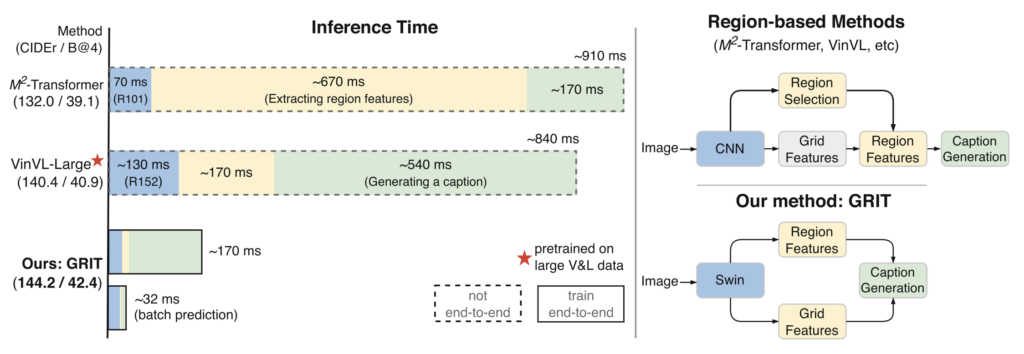
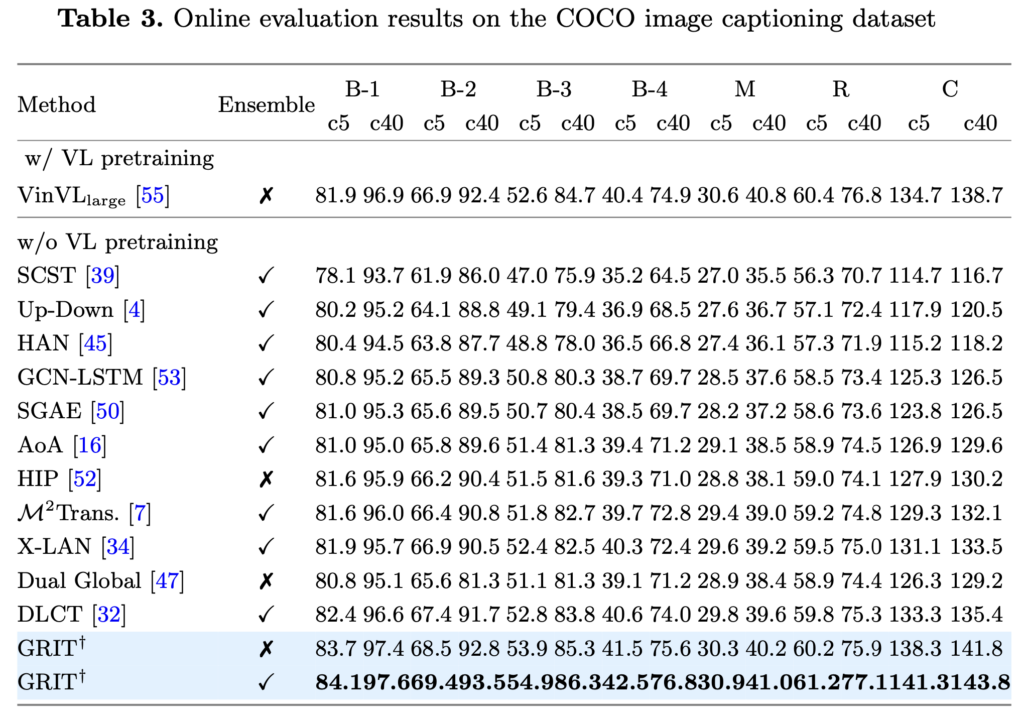
総じてGRITは、Transformerベースの統合的な設計と、2種類の視覚情報の効果的な活用によって、画像キャプショニングの性能と効率の両方を向上させた点で非常に意義深い。今後の応用として、視覚と言語の融合が求められる幅広い分野への展開が期待される。
発表論文
Nguyen, Van-Quang, Masanori Suganuma, and Takayuki Okatani. “Grit: Faster and better image captioning transformer using dual visual features.” European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
@inproceedings{nguyen2022grit,
title={Grit: Faster and better image captioning transformer using dual visual features},
author={Nguyen, Van-Quang and Suganuma, Masanori and Okatani, Takayuki},
booktitle={European Conference on Computer Vision},
pages={167--184},
year={2022},
organization={Springer}
}